マスクの前処理方式(Native)
最終更新: 2024年12月19日
Cubism 5 SDK 以降では、一部のクラス名などが変更されています
詳細についてはCHANGELOGを参照してください。
Live2D Cubism SDK for Nativeでは、スマートフォンなどで描画速度を維持するために、
モデル描画処理の最初に一枚のマスクバッファに対してすべてのマスク形状を描画する『前処理方式』を採用しています。
原則的な描画方法では、マスクを必要とするDrawableを描画するタイミングで、その都度マスク形状を描画します(図参照)。
この方法では、Drawableがマスクを必要とするたびにレンダーターゲットの切り替え・バッファのクリアなど比較的高コストな処理が発生することになります。
そのため、スマートフォンなどで描画速度が低下する原因になる場合があります。
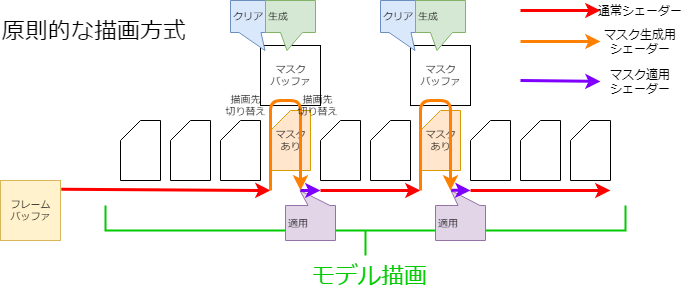
しかし、前もってマスクを用意するだけではマスクバッファが複数枚必要になり、メモリーを圧迫することになります。
この点を解決するため、一枚のマスクバッファに対して以下の処理を行うことで、まるで複数枚のマスクバッファを利用しているかのように扱いつつ、メモリーの圧迫を抑えることができます。
マスクの統合
前もってすべてのマスクを生成するため、同じマスク指定を受けているDrawableは同一のマスク画像を使うことで生成する枚数を抑えられます。

この処理はCubismRenderer_OpenGLES2::Initialize関数呼び出しの中で
CubismClippingManager::Initialize関数によって行われます。
template <class T_ClippingContext, class T_OffscreenSurface>
void CubismClippingManager<T_ClippingContext, T_OffscreenSurface>::Initialize(CubismModel& model, const csmInt32 maskBufferCount)
{
_renderTextureCount = maskBufferCount;
// レンダーテクスチャのクリアフラグの設定
for (csmInt32 i = 0; i < _renderTextureCount; ++i)
{
_clearedMaskBufferFlags.PushBack(false);
}
//クリッピングマスクを使う描画オブジェクトを全て登録する
//クリッピングマスクは、通常数個程度に限定して使うものとする
for (csmInt32 i = 0; i < model.GetDrawableCount(); i++)
{
if (model.GetDrawableMaskCounts()[i] <= 0)
{
//クリッピングマスクが使用されていないアートメッシュ(多くの場合使用しない)
_clippingContextListForDraw.PushBack(NULL);
continue;
}
// 既にあるClipContextと同じかチェックする
T_ClippingContext* cc = FindSameClip(model.GetDrawableMasks()[i], model.GetDrawableMaskCounts()[i]);
if (cc == NULL)
{
// 同一のマスクが存在していない場合は生成する
cc = CSM_NEW T_ClippingContext(this, model, model.GetDrawableMasks()[i], model.GetDrawableMaskCounts()[i]);
_clippingContextListForMask.PushBack(cc);
}
cc->AddClippedDrawable(i);
_clippingContextListForDraw.PushBack(cc);
}
}
複数枚のマスク用テクスチャの利用
Cubism SDK for Native R6以降では、マスク用テクスチャを任意で複数枚使用することができます。
そのため、R5までに存在したマスクの使用上限数である36枚を超過したマスクをモデルに設定しても、SDK上で正常に表示させることができるようになります。
ただし、マスク用テクスチャを2枚以上使用した場合、マスク用テクスチャ1枚に対して生成されるマスクの上限数は32枚までとなります。
(1枚のみ使用する場合のマスクの上限数は36枚です。こちらの詳細は後述します)
仮にマスク用テクスチャを2枚使用した場合、使用できるマスクの上限数は32 * 2の64枚になります。
マスク用テクスチャを複数枚使用するための設定は以下のようになります。
void CreateRenderer(csmInt32 maskBufferCount = 2);
色情報での分離
マスクバッファは実体として通常のテクスチャバッファなどと同じようにRGBAの映像用配列です。
通常のマスク処理ではこのAチャンネルのみを使用してマスクを適用しますがRGBのチャンネルは使用しません。
そこでRGBAで別々のマスクデータを持つことによって一枚のマスクバッファを4枚のマスクバッファとして取り扱えるようになります。
分割分離
マスク画像が4枚では足りなくなった時、マスクバッファを2分割、4分割、9分割で取り扱うことによってマスクの枚数を増やします。
色情報での分割もあるので4x9の36枚まで違うマスクを保持できるようになっています。
またマスク画像がつぶれるのを防ぐため、マスクの適用を受けるすべてのDrawableの矩形でマスクを描画します。
このため範囲の生成とマスク生成、マスク使用でのマトリックスの生成が必要になります。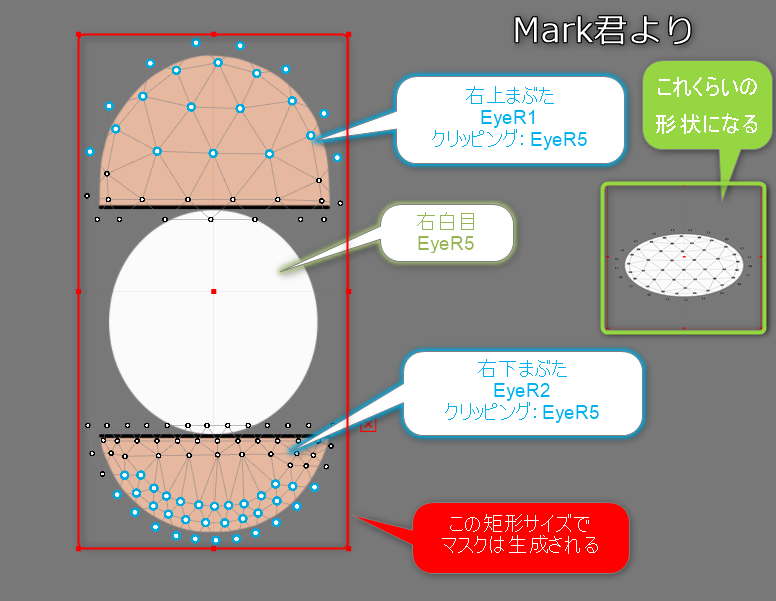
マスク用テクスチャを複数枚利用する場合も分割方式はマスク用テクスチャ1枚のみを利用した場合と同様となります。
ただし、マスク用テクスチャを複数枚利用する場合にはマスク用テクスチャ1枚あたりへのマスクの割り当てを可能な限り等分するようになるため、同じモデルでも描画の品質が上がります。(マスク用テクスチャを増やすと、その分処理コストはかかります)
例えば、マスクが32枚のモデルの場合には通常はマスク用テクスチャ1枚で32枚のマスクを描画しようとしますが、マスク用テクスチャを2枚使った場合のマスクの割り当ては「1枚あたり16枚」となります。
矩形の確認
マスク生成の初めのステップで、マスクごとにマスク適用先すべてが収まる矩形を確認します。
template <class T_ClippingContext, class T_OffscreenSurface>
void CubismClippingManager<T_ClippingContext, T_OffscreenSurface>::CalcClippedDrawTotalBounds(CubismModel& model, T_ClippingContext* clippingContext)
{
// 被クリッピングマスク(マスクされる描画オブジェクト)の全体の矩形
csmFloat32 clippedDrawTotalMinX = FLT_MAX, clippedDrawTotalMinY = FLT_MAX;
csmFloat32 clippedDrawTotalMaxX = -FLT_MAX, clippedDrawTotalMaxY = -FLT_MAX;
// このマスクが実際に必要か判定する
// このクリッピングを利用する「描画オブジェクト」がひとつでも使用可能であればマスクを生成する必要がある
const csmInt32 clippedDrawCount = clippingContext->_clippedDrawableIndexList->GetSize();
for (csmInt32 clippedDrawableIndex = 0; clippedDrawableIndex < clippedDrawCount; clippedDrawableIndex++)
{
// マスクを使用する描画オブジェクトの描画される矩形を求める
const csmInt32 drawableIndex = (*clippingContext->_clippedDrawableIndexList)[clippedDrawableIndex];
csmInt32 drawableVertexCount = model.GetDrawableVertexCount(drawableIndex);
csmFloat32* drawableVertexes = const_cast<csmFloat32*>(model.GetDrawableVertices(drawableIndex));
csmFloat32 minX = FLT_MAX, minY = FLT_MAX;
csmFloat32 maxX = -FLT_MAX, maxY = -FLT_MAX;
csmInt32 loop = drawableVertexCount * Constant::VertexStep;
for (csmInt32 pi = Constant::VertexOffset; pi < loop; pi += Constant::VertexStep)
{
csmFloat32 x = drawableVertexes[pi];
csmFloat32 y = drawableVertexes[pi + 1];
if (x < minX) minX = x;
if (x > maxX) maxX = x;
if (y < minY) minY = y;
if (y > maxY) maxY = y;
}
//
if (minX == FLT_MAX) continue; //有効な点がひとつも取れなかったのでスキップする
// 全体の矩形に反映
if (minX < clippedDrawTotalMinX) clippedDrawTotalMinX = minX;
if (minY < clippedDrawTotalMinY) clippedDrawTotalMinY = minY;
if (maxX > clippedDrawTotalMaxX) clippedDrawTotalMaxX = maxX;
if (maxY > clippedDrawTotalMaxY) clippedDrawTotalMaxY = maxY;
}
if (clippedDrawTotalMinX == FLT_MAX)
{
clippingContext->_allClippedDrawRect->X = 0.0f;
clippingContext->_allClippedDrawRect->Y = 0.0f;
clippingContext->_allClippedDrawRect->Width = 0.0f;
clippingContext->_allClippedDrawRect->Height = 0.0f;
clippingContext->_isUsing = false;
}
else
{
clippingContext->_isUsing = true;
csmFloat32 w = clippedDrawTotalMaxX - clippedDrawTotalMinX;
csmFloat32 h = clippedDrawTotalMaxY - clippedDrawTotalMinY;
clippingContext->_allClippedDrawRect->X = clippedDrawTotalMinX;
clippingContext->_allClippedDrawRect->Y = clippedDrawTotalMinY;
clippingContext->_allClippedDrawRect->Width = w;
clippingContext->_allClippedDrawRect->Height = h;
}
}
色分離、分割分離を受けたレイアウト決定
マスクごとに所属するマスクバッファの色チャンネル、分割位置を定めます。
template <class T_ClippingContext, class T_OffscreenSurface>
void CubismClippingManager<T_ClippingContext, T_OffscreenSurface>::SetupLayoutBounds(csmInt32 usingClipCount) const
{
const csmInt32 useClippingMaskMaxCount = _renderTextureCount <= 1
? ClippingMaskMaxCountOnDefault
: ClippingMaskMaxCountOnMultiRenderTexture * _renderTextureCount;
if (usingClipCount <= 0 || usingClipCount > useClippingMaskMaxCount)
{
if (usingClipCount > useClippingMaskMaxCount)
{
// マスクの制限数の警告を出す
csmInt32 count = usingClipCount - useClippingMaskMaxCount;
CubismLogError("not supported mask count : %d\n[Details] render texture count: %d\n, mask count : %d"
, count, _renderTextureCount, usingClipCount);
}
// この場合は一つのマスクターゲットを毎回クリアして使用する
for (csmUint32 index = 0; index < _clippingContextListForMask.GetSize(); index++)
{
T_ClippingContext* cc = _clippingContextListForMask[index];
cc->_layoutChannelIndex = 0; // どうせ毎回消すので固定で良い
cc->_layoutBounds->X = 0.0f;
cc->_layoutBounds->Y = 0.0f;
cc->_layoutBounds->Width = 1.0f;
cc->_layoutBounds->Height = 1.0f;
cc->_bufferIndex = 0;
}
return;
}
// レンダーテクスチャが1枚なら9分割する(最大36枚)
const csmInt32 layoutCountMaxValue = _renderTextureCount <= 1 ? 9 : 8;
// ひとつのRenderTextureを極力いっぱいに使ってマスクをレイアウトする
// マスクグループの数が4以下ならRGBA各チャンネルに1つずつマスクを配置し、5以上6以下ならRGBAを2,2,1,1と配置する
const csmInt32 countPerSheetDiv = (usingClipCount + _renderTextureCount - 1) / _renderTextureCount; // レンダーテクスチャ1枚あたり何枚割り当てるか(切り上げ)
const csmInt32 reduceLayoutTextureCount = usingClipCount % _renderTextureCount; // レイアウトの数を1枚減らすレンダーテクスチャの数(この数だけのレンダーテクスチャが対象)
// RGBAを順番に使っていく
const csmInt32 divCount = countPerSheetDiv / ColorChannelCount; //1チャンネルに配置する基本のマスク個数
const csmInt32 modCount = countPerSheetDiv % ColorChannelCount; //余り、この番号のチャンネルまでに1つずつ配分する
// RGBAそれぞれのチャンネルを用意していく(0:R , 1:G , 2:B, 3:A, )
csmInt32 curClipIndex = 0; //順番に設定していく
for (csmInt32 renderTextureIndex = 0; renderTextureIndex < _renderTextureCount; renderTextureIndex++)
{
for (csmInt32 channelIndex = 0; channelIndex < ColorChannelCount; channelIndex++)
{
// このチャンネルにレイアウトする数
// NOTE: レイアウト数 = 1チャンネルに配置する基本のマスク + 余りのマスクを置くチャンネルなら1つ追加
csmInt32 layoutCount = divCount + (channelIndex < modCount ? 1 : 0);
// レイアウトの数を1枚減らす場合にそれを行うチャンネルを決定
// divが0の時は正常なインデックスの範囲内になるように調整
const csmInt32 checkChannelIndex = modCount + (divCount < 1 ? -1 : 0);
// 今回が対象のチャンネルかつ、レイアウトの数を1枚減らすレンダーテクスチャが存在する場合
if (channelIndex == checkChannelIndex && reduceLayoutTextureCount > 0)
{
// 現在のレンダーテクスチャが、対象のレンダーテクスチャであればレイアウトの数を1枚減らす
layoutCount -= !(renderTextureIndex < reduceLayoutTextureCount) ? 1 : 0;
}
// 分割方法を決定する
if (layoutCount == 0)
{
// 何もしない
}
else if (layoutCount == 1)
{
//全てをそのまま使う
T_ClippingContext* cc = _clippingContextListForMask[curClipIndex++];
cc->_layoutChannelIndex = channelIndex;
cc->_layoutBounds->X = 0.0f;
cc->_layoutBounds->Y = 0.0f;
cc->_layoutBounds->Width = 1.0f;
cc->_layoutBounds->Height = 1.0f;
cc->_bufferIndex = renderTextureIndex;
}
else if (layoutCount == 2)
{
for (csmInt32 i = 0; i < layoutCount; i++)
{
const csmInt32 xpos = i % 2;
T_ClippingContext* cc = _clippingContextListForMask[curClipIndex++];
cc->_layoutChannelIndex = channelIndex;
cc->_layoutBounds->X = xpos * 0.5f;
cc->_layoutBounds->Y = 0.0f;
cc->_layoutBounds->Width = 0.5f;
cc->_layoutBounds->Height = 1.0f;
cc->_bufferIndex = renderTextureIndex;
//UVを2つに分解して使う
}
}
else if (layoutCount <= 4)
{
//4分割して使う
for (csmInt32 i = 0; i < layoutCount; i++)
{
const csmInt32 xpos = i % 2;
const csmInt32 ypos = i / 2;
T_ClippingContext* cc = _clippingContextListForMask[curClipIndex++];
cc->_layoutChannelIndex = channelIndex;
cc->_layoutBounds->X = xpos * 0.5f;
cc->_layoutBounds->Y = ypos * 0.5f;
cc->_layoutBounds->Width = 0.5f;
cc->_layoutBounds->Height = 0.5f;
cc->_bufferIndex = renderTextureIndex;
}
}
else if (layoutCount <= layoutCountMaxValue)
{
//9分割して使う
for (csmInt32 i = 0; i < layoutCount; i++)
{
const csmInt32 xpos = i % 3;
const csmInt32 ypos = i / 3;
T_ClippingContext* cc = _clippingContextListForMask[curClipIndex++];
cc->_layoutChannelIndex = channelIndex;
cc->_layoutBounds->X = xpos / 3.0f;
cc->_layoutBounds->Y = ypos / 3.0f;
cc->_layoutBounds->Width = 1.0f / 3.0f;
cc->_layoutBounds->Height = 1.0f / 3.0f;
cc->_bufferIndex = renderTextureIndex;
}
}
// マスクの制限枚数を超えた場合の処理
else
{
csmInt32 count = usingClipCount - useClippingMaskMaxCount;
CubismLogError("not supported mask count : %d\n[Details] render texture count: %d\n, mask count : %d"
, count, _renderTextureCount, usingClipCount);
// 開発モードの場合は停止させる
CSM_ASSERT(0);
// 引き続き実行する場合、 SetupShaderProgramでオーバーアクセスが発生するので仕方なく適当に入れておく
// もちろん描画結果はろくなことにならない
for (csmInt32 i = 0; i < layoutCount; i++)
{
T_ClippingContext* cc = _clippingContextListForMask[curClipIndex++];
cc->_layoutChannelIndex = 0;
cc->_layoutBounds->X = 0.0f;
cc->_layoutBounds->Y = 0.0f;
cc->_layoutBounds->Width = 1.0f;
cc->_layoutBounds->Height = 1.0f;
cc->_bufferIndex = 0;
}
}
}
}
}
マスク描画、マスク使用のマトリックス生成
描画前に調べた矩形範囲と所属場所に基づいてマスク生成用、マスク使用用の変換マトリックスを用意します。
// --- 実際に1つのマスクを描く ---
T_ClippingContext* clipContext = _clippingContextListForMask[clipIndex];
csmRectF* allClippedDrawRect = clipContext->_allClippedDrawRect; //このマスクを使う、全ての描画オブジェクトの論理座標上の囲み矩形
csmRectF* layoutBoundsOnTex01 = clipContext->_layoutBounds; //この中にマスクを収める
const csmFloat32 MARGIN = 0.05f;
csmFloat32 scaleX = 0.0f;
csmFloat32 scaleY = 0.0f;
const csmFloat32 ppu = model.GetPixelsPerUnit();
const csmFloat32 maskPixelWidth = clipContext->GetClippingManager()->_clippingMaskBufferSize.X;
const csmFloat32 maskPixelHeight = clipContext->GetClippingManager()->_clippingMaskBufferSize.Y;
const csmFloat32 physicalMaskWidth = layoutBoundsOnTex01->Width * maskPixelWidth;
const csmFloat32 physicalMaskHeight = layoutBoundsOnTex01->Height * maskPixelHeight;
_tmpBoundsOnModel.SetRect(allClippedDrawRect);
if (_tmpBoundsOnModel.Width * ppu > physicalMaskWidth)
{
_tmpBoundsOnModel.Expand(allClippedDrawRect->Width * MARGIN, 0.0f);
scaleX = layoutBoundsOnTex01->Width / _tmpBoundsOnModel.Width;
}
else
{
scaleX = ppu / physicalMaskWidth;
}
if (_tmpBoundsOnModel.Height * ppu > physicalMaskHeight)
{
_tmpBoundsOnModel.Expand(0.0f, allClippedDrawRect->Height * MARGIN);
scaleY = layoutBoundsOnTex01->Height / _tmpBoundsOnModel.Height;
}
else
{
scaleY = ppu / physicalMaskHeight;
}
// マスク生成時に使う行列を求める
createMatrixForMask(isRightHanded, layoutBoundsOnTex01, scaleX, scaleY);
clipContext->_matrixForMask.SetMatrix(_tmpMatrixForMask.GetArray());
clipContext->_matrixForDraw.SetMatrix(_tmpMatrixForDraw.GetArray());
マスクバッファの動的なサイズ変更

GLES2レンダラには、実行時にマスクバッファのサイズを変更するAPIを用意してあります。
現状、マスクバッファのサイズは初期値として256*256(ピクセル)を設定していますが、マスク生成領域を9枚に切るような場合、
85*85(ピクセル)の矩形領域に描画したマスク形状を、更に拡大してクリッピング領域として使用します。
その結果、クリッピング結果のエッジがぼやけたり、滲みのような現象が見られます。
それを解決する方法として、マスクバッファのサイズをプログラム実行時に変更するAPIを用意しています。
例えば、マスクバッファのサイズを256*256 ⇒ 1024*1024とすることで、マスク生成領域を9枚に切るような場合、341*341の矩形領域にマスク形状を描画することができるので、
拡大してクリッピング領域として使用しても、クリッピング結果のエッジのぼやけやにじみを解消することができます。
※マスクバッファのサイズを大きくする ⇒ 処理するピクセルが増えると速度は遅くなるが、描画結果は綺麗になる。
※マスクバッファのサイズを小さくする ⇒ 処理するピクセルが減るので速度は速くなるが、描画結果は汚くなる。
void CubismRenderer_OpenGLES2::SetClippingMaskBufferSize(csmFloat32 width, csmFloat32 height)
{
if (_clippingManager == NULL)
{
return;
}
// インスタンス破棄前にレンダーテクスチャの数を保存
const csmInt32 renderTextureCount = _clippingManager->GetRenderTextureCount();
//OffscreenSurfaceのサイズを変更するためにインスタンスを破棄・再作成する
CSM_DELETE_SELF(CubismClippingManager_OpenGLES2, _clippingManager);
_clippingManager = CSM_NEW CubismClippingManager_OpenGLES2();
_clippingManager->SetClippingMaskBufferSize(width, height);
_clippingManager->Initialize(
*GetModel(),
renderTextureCount
);
}
前処理方式によってパフォーマンスの向上が見込める理由
携帯端末特有の事情として、GPUに対するClear命令やレンダリングターゲット切り替え命令の処理コストが、他の命令よりも高い場合があります。
原則的方式で描画するときには、これら処理コストが高い命令を、マスクが必要になるDrawableの数だけ実行することになります。
しかし、前処理方式の場合では、これらの命令を実行する回数を削減することができるので、スマートフォンなどでのパフォーマンスの向上が見込めます。
実際にその効果を把握するため、レンダリングにおける各処理単位での時間コストを測定してみます。
測定方法として、以下に示すソースコードで確認します。 レイヤーはビルドごと分離して計測します。
また、テスト対象のモデルはHaru一体です。
測定する端末としてはAndroid機を2種類、Windows機を1種類用意しました。
測定はAndroid側でclock_gettime関数、Windows側でQueryPerformanceCounter関数を使用して バッファに結果をキャッシュして平均値を計算するという方針で測定します。
クリッピングマスク生成部(レイヤー1)
void CubismClippingManager_OpenGLES2::SetupClippingContext(CubismModel& model, CubismRenderer_OpenGLES2* renderer)
{
・
・
・
{ // ★描画ターゲットの切り替えの測定
P_TIME1(ProcessingTime cl(s_switch);)
// ---------- マスク描画処理 -----------
// マスク用RenderTextureをactiveにセット
glBindFramebuffer(GL_FRAMEBUFFER, _maskRenderTexture);
}
{ // ★バッファのクリア(塗りつぶし処理)の測定
P_TIME1(ProcessingTime cl(s_clear);)
// マスクをクリアする
//(仮仕様) 1が無効(描かれない)領域、0が有効(描かれる)領域。(シェーダで Cd*Csで0に近い値をかけてマスクを作る。1をかけると何も起こらない)
glClearColor(0.0f, 0.0f, 0.0f, 0.0f);
glClear(GL_COLOR_BUFFER_BIT);
}
・
・
・
{ // ★描画ターゲットの切り替えの測定2
P_TIME1(ProcessingTime cl(s_switch);)
// --- 後処理 ---
glBindFramebuffer(GL_FRAMEBUFFER, oldFBO); // 描画対象を戻す
}
・
・
・
}
CubismClippingManager_OpenGLES2::SetupClippingContextでは描画ターゲットの切り替えや塗りつぶしの時間を測定します。
モデル描画全体(レイヤー1、2混在)
void CubismRenderer_OpenGLES2::DoDrawModel()
{
{ // ★マスクバッファ生成全体の測定
P_TIME2(ProcessingTime makemask(s_maskmake);)
if (_clippingManager != NULL)
{
PreDraw();
_clippingManager->SetupClippingContext(*GetModel(), this);
}
}
{ // ★描画前処理の測定
P_TIME1(ProcessingTime makemask(s_predraw);)
// 上記クリッピング処理内でも一度PreDrawを呼ぶので注意!!
PreDraw();
}
const csmInt32 drawableCount = GetModel()->GetDrawableCount();
const csmInt32* renderOrder = GetModel()->GetDrawableRenderOrders();
{ // ★ソートの時間を測定
P_TIME1(ProcessingTime makemask(s_sort);)
// インデックスを描画順でソート
for (csmInt32 i = 0; i < drawableCount; ++i)
{
const csmInt32 order = renderOrder[i];
_sortedDrawableIndexList[order] = i;
}
}
{ // ★マスク以外の描画時間測定
P_TIME2(ProcessingTime makemask(s_draw);)
// 描画
for (csmInt32 i = 0; i < drawableCount; ++i)
{
const csmInt32 drawableIndex = _sortedDrawableIndexList[i];
// クリッピングマスクをセットする
SetClippingContextBufferForDraw(clipContext);
IsCulling(GetModel()->GetDrawableCulling(drawableIndex) != 0);
DrawMeshOpenGL(*GetModel(), drawableIndex);
}
}
{ // ★描画後処理の測定
P_TIME1(ProcessingTime makemask(s_post);)
//
PostDraw();
}
}
描画前、ソート、描画後処理の測定をします。
レイヤーを分けてマスク生成とそれ以外の描画という大枠でも測定します。
メッシュの描画(レイヤー1)
void CubismRenderer_OpenGLES2::DrawMeshOpenGL(const CubismModel& model, const csmInt32 index)
{
・
・
・
{ // ★シェーダーへのデータのセット時間を測定
P_TIME1(ProcessingTime sharder(s_sharder);)
if (IsGeneratingMask()) // マスク生成時
{
CubismShader_OpenGLES2::GetInstance()->SetupShaderProgramForMask(this, model, index);
}
else
{
CubismShader_OpenGLES2::GetInstance()->SetupShaderProgramForDraw(this, model, index);
}
}
{ // ★描画命令単体の時間測定
P_TIME1(ProcessingTime gldraw(s_gldraw);)
// ポリゴンメッシュを描画する
glDrawElements(GL_TRIANGLES, indexCount, GL_UNSIGNED_SHORT, indexArray);
}
// 後処理
glUseProgram(0);
SetClippingContextBufferForDraw(NULL);
SetClippingContextBufferForMask(NULL);
}
CubismRenderer_OpenGLES2::DrawMeshではシェーダーへの設定時間と描画命令単一時間を測定します。
レイヤー3
void LAppModel::Update()
{
{
P_TIME3(ProcessingTime up(s_paramup);)
const csmFloat32 deltaTimeSeconds = LAppPal::GetDeltaTime();
_userTimeSeconds += deltaTimeSeconds;
・
・
・
// ポーズの設定
if (_pose != NULL)
{
_pose->UpdateParameters(_model, deltaTimeSeconds);
}
}
{
P_TIME3(ProcessingTime ren(s_modelup);)
_model->Update();
}
}
void LAppModel::Draw(CubismMatrix44& matrix)
{
P_TIME3(ProcessingTime ren(s_rendering);)
matrix.MultiplyByMatrix(_modelMatrix);
GetRenderer<Rendering::CubismRenderer_OpenGLES2>()->SetMvpMatrix(&matrix);
DoDraw();
}
大枠としてUpdateの流れを
パラメーター計算、モデルのアップデート、レンダリングの3つに分けてみていきます。
結果
| Android1 | Android2 | Winpc1 | |
| L1clear | 1781.20 | 218.80 | 26.80 |
| L1gldraw | 45.47 | 51.63 | 10.58 |
| L1sharder | 12.31 | 9.34 | 5.37 |
| L1post | 1.50 | 1.00 | 0.10 |
| L1switch | 10.70 | 56.30 | 7.80 |
| L1predraw | 15.90 | 8.20 | 2.20 |
| L1sort | 7.60 | 7.00 | 0.60 |
| L2MaskMake | 2686.80 | 1357.60 | 318.50 |
| L2draw | 4004.10 | 4013.20 | 1217.00 |
| L3paramupdate | 392.00 | 375.40 | 89.70 |
| L3modelupdate | 1357.50 | 1410.90 | 1070.40 |
| L3rendering | 6715.70 | 5233.70 | 1892.00 |
上の表は先に示した部分の実行時間です。
携帯端末はClearのコストが高かったり、レンダリングターゲットの切り替えが他の命令に比べて重たいことがわかります。
この重い命令が原則的な方法で描画するときにはマスクが必要になるDrawableの数だけ走ります。
この計算が一回で済むためスマートフォンなどでのパフォーマンスの向上が見込めます。
マスクの処理を高精細な方式に切り替える
前述の通り、描画の度にマスクを生成する方式だと、低スペック端末ではパフォーマンスに影響があります。
しかし、最終的に動画として出力する場合のように、ランタイムでのパフォーマンスよりも画面の品質の方を重視する場合はこちらの方式のほうが適しています。
2018/12/20以降のSDKでは、マスクの処理を高精細な方式に切り替える事ができます。
高精細な方式に切り替えるには、以下のAPIにtrueを渡します。
CubismRenderer::UseHighPrecisionMask()